百川大模型是百川智能于2023年7月发布的中国最大中文语言模型。该模型在短短三个月内迅速成长为中国最大、全球领先的中文大模型,并在2023年10月的发布会上一举打破了世界纪录,成为中国首个在多个领域取得最好成绩的大模型。
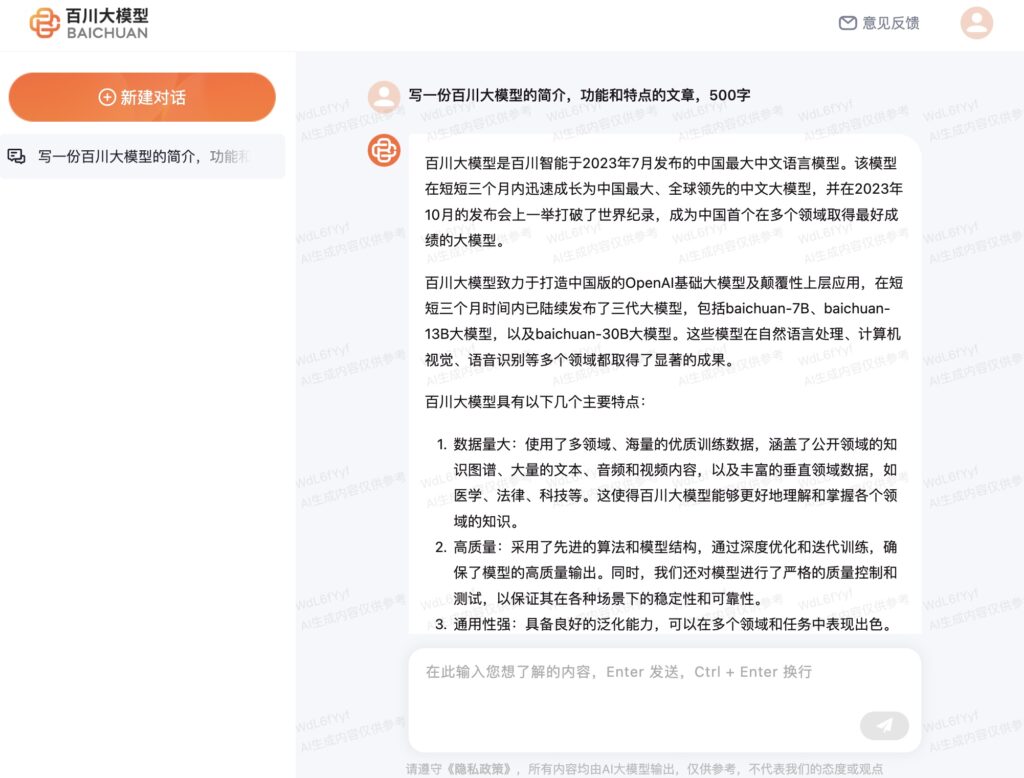
百川大模型致力于打造中国版的OpenAI基础大模型及颠覆性上层应用,在短短三个月时间内已陆续发布了三代大模型,包括baichuan-7B、baichuan-13B大模型,以及baichuan-30B大模型。这些模型在自然语言处理、计算机视觉、语音识别等多个领域都取得了显著的成果。
百川大模型具有以下几个主要特点:
- 数据量大:使用了多领域、海量的优质训练数据,涵盖了公开领域的知识图谱、大量的文本、音频和视频内容,以及丰富的垂直领域数据,如医学、法律、科技等。这使得百川大模型能够更好地理解和掌握各个领域的知识。
- 高质量:采用了先进的算法和模型结构,通过深度优化和迭代训练,确保了模型的高质量输出。同时,我们还对模型进行了严格的质量控制和测试,以保证其在各种场景下的稳定性和可靠性。
- 通用性强:具备良好的泛化能力,可以在多个领域和任务中表现出色。无论是语言翻译、对话生成、文本摘要、情感分析还是图像分类等任务,百川大模型都能轻松应对。
- 可定制性:支持多种开发方式,可以根据不同需求进行个性化定制。例如,可以通过微调模型参数来实现特定领域的精度提升;也可以将模型与其他系统集成,以满足特定的业务需求。
- 易用性高:提供了丰富的接口和工具,方便用户使用和集成。目前,百川已经开放了API、SDK和工具集,并提供在线试用平台,让开发者可以快速上手和部署。
- 安全可控:遵循相关法规和政策要求,保护用户隐私和数据安全。同时,我们提供了完善的技术支持和服务体系,确保用户在使用过程中无后顾之忧。
当前网址国内可以直接访问