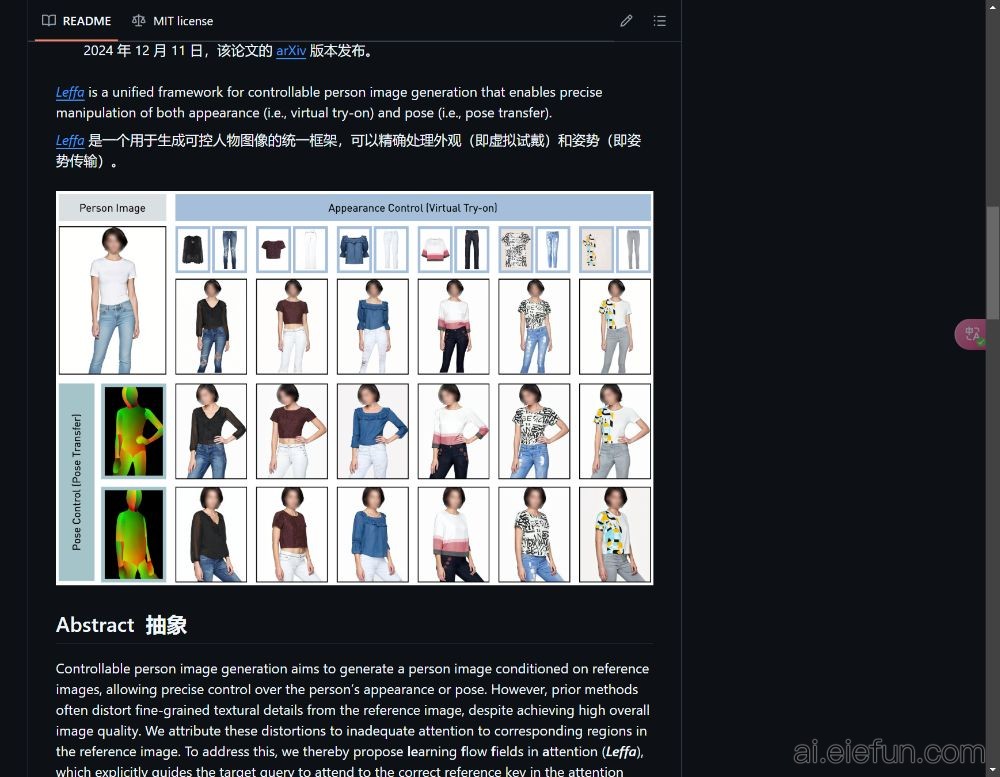
Leffa是一个创新的可控人物图像生成框架,通过在注意力机制中学习流场,实现对人物外观和姿势的精确控制。该项目旨在解决传统方法中细粒度纹理失真的问题,提供高质量的人物图像生成。通过引入正则化损失,Leffa能够有效地指导模型关注参考图像中的关键区域,从而减少细节失真,同时保持整体图像质量。
Leffa支持多种应用,包括虚拟试戴和姿势转移,使用户能够根据特定需求生成个性化的人物图像。例如,通过输入参考图像,用户可以调整目标人物的服装或姿势,达到更好的视觉效果。此外,该框架具有模型无关性,可以与其他扩散模型结合使用,提升其性能。
网站还提供了丰富的资源,包括论文、代码和演示,让研究人员和开发者能够快速上手。用户只需创建conda环境并安装相关依赖,即可在本地运行代码进行指标评估。同时,通过与ComfyUI等工具的集成,Leffa为用户提供了更便捷的操作体验。